Граф – это математический термин, означающий набор вершин, и соединяющих их ребер. Простейший граф выглядит так:
Рис. 17. Простейший граф
Обратите внимание, что ребро является направленным.
Очевидно, что структура такого графа идеально соответствует структуре триплета: вершины – это подлежащее и дополнение, а ребро – сказуемое. Например, триплет «Собака является животным» можно изобразить так:
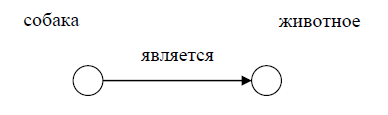
Рис. 18. Логическое выражение, представленное в виде графа
Таким образом, любую онтологию можно изобразить в виде графа. Проиллюстрируем это на примере из предыдущей главы.
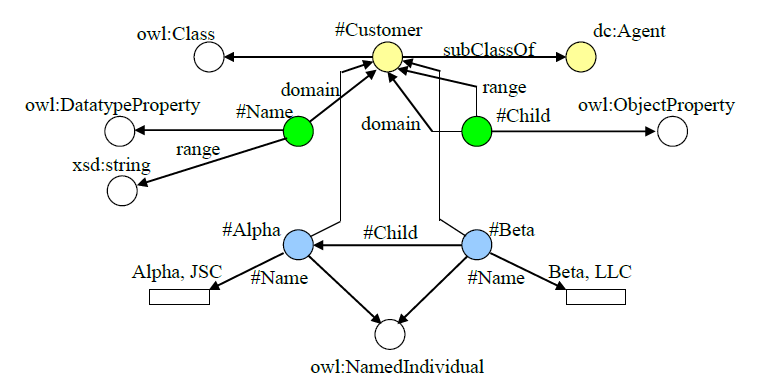 Рис. 19. Модель, представленная в виде графа
Рис. 19. Модель, представленная в виде графаГлядя на подобные изображения, важно понимать, что вершина соответствует, фактически, уникальному идентификатору объекта (за исключением вершин-литералов, которые мы показали прямоугольниками). Она не содержит никакой другой информации; все приписанные ей свойства задаются отдельными ребрами графа. Некоторые вершины мы выделили цветом только для удобства восприятия.
Правильность изображения нашей модели легко проверить, посчитав число ребер. Их 15, столько же, сколько триплетов в таблице из предыдущей главы.
Поскольку полное графическое представление модели обычно оказывается слишком сложным, его упрощают – не показывают ребра, отображающие тип элемента, указывающие на литералы и т.д.
Заметим также, что в нашей модели сущности-свойства (#Name, #Child) присутствуют в двух ролях – в качестве вершин, что соответствует их описанию, и в качестве ребер, когда выполняется присвоение значения свойства конкретному объекту.
Такое представление семантической модели определяет способ построения запросов к ней, реализованный в языке SPARQL. Мы уже видели пример простейшего SPARQL-запроса:
SELECT * WHERE { ?a ?b ?c }
Слова SELECT * WHERE понятны всем, кто знаком с SQL – это выборка всех результатов из набора строк (в SQL) или триплетов (в SPARQL), отвечающих условиям отбора. Условия отбора, в случае SPARQL – это выражение, заключенное в фигурные скобки. Оно определяет паттерн, или шаблон, которому должны соответствовать триплеты. Значения, начинающиеся на вопросительный знак – это переменные. Они могут принимать любое значение; эти значения и будут возвращены в результате запроса. Поскольку все три позиции в нашем запросе заняты переменными – все три элемента триплета могут быть любыми. Значит, такой запрос вернет все содержимое онтологии (не следует злоупотреблять такими запросами на больших онтологиях).
Приведем несколько примеров осмысленных SPARQL-запросов. Предположим, мы хотим узнать, какой тип имеет объект #Alpha:
SELECT * WHERE { <http://example.com/#alpha> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?c }
Для читаемости, перед запросом можно объявить префиксы. Тогда наш запрос будет выглядеть так:
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema>
SELECT * WHERE { <http://example.com/#alpha> rdfs:type ?c }
Результатом запроса будут значения переменной ?c – единственной оставшейся неизвестной:
| ?c |
| <http://www.w3.org/2002/07/owl#NamedIndividual> |
| <http://example.com/#Customer> |
Чтобы получить список всех членов класса Customer, нужно выполнить такой запрос:
SELECT * WHERE { ?cust rdfs:type }
Результатом будут URI клиентов:
| ?cust |
| <http://example.com/#alpha> |
| <http://example.com/#beta> |
Предположим, что мы хотим одновременно с уникальным идентификатором клиентов получить их имена. Тогда в запросе нужно будет указать паттерн, соответствующий двум ребрам графа:
SELECT * WHERE { ?cust rdfs:type <http://example.com/#Customer>.
?cust <http://example.com/#Name> ?name }
Как мы видим, паттерны триплетов отделяются друг от друга точкой. Результат выполнения этого запроса будет таким:
| ?cust | ?name |
| <http://example.com/#alpha> | “Alpha, JSC” |
| <http://example.com/#beta> | “Beta, LLC” |
Еще более усложним запрос. Пусть нам нужны сразу имена вышестоящих структур для каждой компании. При этом URI мы не хотим видеть в результатах запроса. Нужно принимать во внимание, что у некоторых компаний может не быть вышестоящих структур, так что у паттерна появляется опциональная часть, которая может присутствовать не у всех результатов. Запрос будет выглядеть так:
SELECT ?name ?parent_name WHERE {
?cust rdfs:type <http://example.com/#Customer>.
?cust <http://example.com/#Name> ?name.
OPTIONAL { ?cust <http://example.com/#Child> ?parent.
?parent <http://example.com/#Name> ?parent_name }
}
Обратим внимание на следующие детали синтаксиса:
- Вместо * в списке выбираемых значений можно указать через пробел имена тех переменных, которые нужны в списке возвращаемых значений. Остальные переменные используются в структуре паттернов запроса, но выданы в виде результатов не будут.
- Клауза OPTIONAL (в запросе их может быть несколько) используется для задания дополнительных паттернов, которым могут, но не обязаны соответствовать результаты запроса. Это очень полезно в случаях, когда выбираются объекты вместе с их свойствами, но свойства заданы не у каждого объекта. Если свойство поместить в основной паттерн, а не в OPTIONAL, то в результат попадут только те объекты, у которых значение свойства установлено.
Результат выполнения этого запроса будет таким:
| ?name | ?parent_name |
| “Alpha, JSC” | |
| “Beta, LLC” | “Alpha, JSC” |
| ?name | ?parent_name |
| “Alpha, JSC” | |
| “Beta, LLC” | “Alpha, JSC” |
| “Beta, LLC” | “Gamma” |
Как мы видим, для каждой комбинации вершин и ребер графов, отвечающих результатам запроса, выводится отдельная строка результата. Таким образом, одна и та же сущность, одна и та же часть графа может фигурировать в результатах запроса несколько раз. Чем сложнее запрос, тем серьезнее будет его перегруженность повторяющимися результатами. Облегчить жизнь помогает выражение SELECT DISTINCT, выдающее только уникальные результаты запроса. Полезно также сокращать число возвращаемых запросом переменных.
Чтобы лучше понять механизм выполнения SPARQL-запроса, посмотрим на то, как содержащийся в запросе паттерн применяется к вершинам и ребрам графа – на примере последнего запроса:
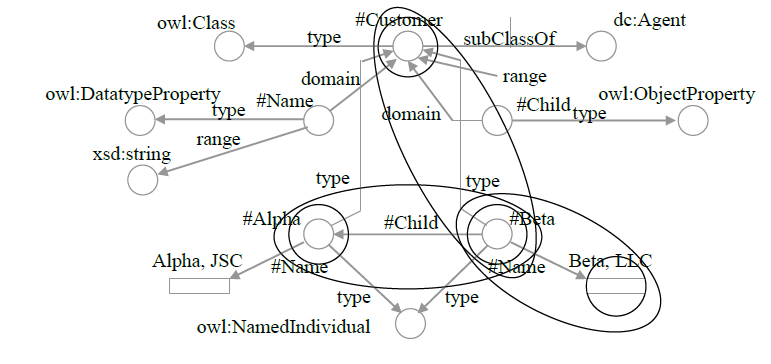
Рис. 20. Выполнение SPARQL-запроса – поиск ребер графа, отвечающих паттернам
На рис. 20 показана только одна часть графа, соответствующая этому запросу. Однако легко себе представить механизм выполнения SPARQL-запроса, как «примерку» паттерна ко всем возможным комбинациям триплетов, существующим в модели.
К более глубокому рассмотрению синтаксиса SPARQL мы еще вернемся, а пока дадим краткий обзор некоторых полезных возможностей этого языка. Отсортируем результаты запроса на список всех клиентов по названию клиента, и выведем 10 результатов, начиная с 5-го:
SELECT * WHERE { ?cust rdfs:type <http://example.com/#Customer>.
?cust <http://example.com/#Name> ?name }
ORDER BY ASC(?name) OFFSET 5 LIMIT 10
Результаты запроса можно фильтровать при помощи клаузы FILTER. Например, нам интересны только те клиенты, в названии которых содержится выражение LLC:
SELECT * WHERE { ?cust rdfs:type <http://example.com/#Customer>.
?cust <http://example.com/#Name> ?name
FILTER(CONTAINS(STR(?name), "LLC")) }
При фильтрации можно сравнивать числовые значения, выполнять математические операции, но при этом необходимо следить за типами – чаще всего, их нужно задавать в явном виде, используя оператор ^^. Обратите внимание, что в данном случае переменная ?name явно приводится к строковому типу.
Завершим рассмотрение темы SPARQL примерами запросов на добавление и удаление данных в онтологию. Запрос на добавление данных выглядит просто:
INSERT DATA { <http://example.com/#alpha> <http://example.com/#Name> "Alpha, JSC".
<http://example.com/#beta> <http://example.com/#Name> "Beta, LLC" }
Аналога SQL-запроса UPDATE в SPARQL нет, данные можно только удалять или добавлять. Поэтому, если возникает необходимость внести изменения в уже существующие триплеты, существующие данные нужно сначала удалить:
DELETE WHERE { <http://example.com/#beta> ?b ?c }
Этот запрос удалит всю информацию о клиенте Beta (но не удалит ссылки на него с других объектов). По понятным причинам, в запросе INSERT не могут использоваться переменные, а в запросе DELETE – могут.
Существует также запрос CONSTRUCT, аналогичный SELECT, но возвращающий результаты не в виде таблицы, а в виде нового RDF-графа (фактически – в виде файла).
Проверить существование решений у SPARQL-паттерна можно при помощи запроса ASK, возвращающего true, если есть хотя бы одно решение, и false в ином случае. Например, узнаем, существуют ли компании, имеющие родительскую организацию:
ASK { ?cust <http://example.com/#Child> ?parent }
На нашей модели результатом такого запроса будет true, истина.
В этой главе мы рассмотрели обычный режим работы с хранилищем триплетов посредством точки доступа SPARQL. В этом режиме точка работает подобно обычной базе данных, то есть возвращает ровно ту информацию, которая была в нее помещена. Между тем, мощь семантических технологий заключается в возможности автоматического получения логических выводов.
Следующий раздел: Машины и правила логического вывода